
How to use grep in Linux
grep "string to search for" filenamegrep -i "once" bitlaunch.txtgrep 'once\|upon' bitlaunch.txtThe grep command is one of the most powerful and widely used tools in Linux. In addition to simple searches, it supports powerful options that enhance its functionality, such as recursive searches through directories, case-insensitive matching, and the use of regular expressions for complex pattern detection.
This guide explores its essential features, provides practical grep examples, and helps you get started with advanced techniques to maximize your grep use. While this guide uses Linux, the grep command in Unix works similarly, so these workflows should be relevant for macOS and BSD, too.
What does grep do in Linux?
Grep (global regular expression print) is a Linux command used to search for specific patterns, words, or phrases within files or output. You can use it case-sensitively or insensitively, highlight matches, and use a form of complex pattern matching called regular expressions.
How does grep work?
grep searches for patterns in each listed file, checking whether each line matches the pattern and highlighting the ones that do. This is perhaps best illustrated by an example. Let's say we have a file, server.log, and need to search it for errors.
1: Starting server...
2: Connection established.
3: ERROR: Failed to load configuration.
4: Warning: Low disk space.
5: Error: Disk write failed.We ask grep to search for the "ERROR" case-insensitively to find all occurrences. Grep then does the following:
- Reads the file: Grep starts going through server.log line by line.
- It finds no match on line 1 or 2, a match on line 3, no match on line 4, and a match on line 5 (case-insensitive).
- Grep outputs only the matching lines with their line number next to them. It provides context surrounding the lines if you specify so in your command.
This is a simple use case, of course. Below, we'll get into some more complex things you can do with grep.
Why is the grep command used?
Admins and developers find grep an essential tool when scraping log files for specific incidents or checking for specific occurrences in a file's code. However, grep can also help data analysts find rows or patterns in datasets, academics find references, writers search manuscripts, etc. Anybody who needs to find something specific in a large file can benefit from grep.
How to use the grep command in Linux
Grep commands can look very complex, but once you understand the basic command structure, options, and regular expression syntax, it's fairly intuitive.
Grep syntax and basic command structure
As we mentioned, there are several different ways you can use grep in files.
The basic grep syntax is as follows:
grep "string to search for" filenameIf your file is located in a different path to your terminal, you should specify where it is. For example:
grep "string to search for" /root/etc/filenameThis grep command will return strings that are an exact match, including capitalization. You can modify this using the options below.
Options available in grep
The grep command in Linux allows for advanced searches by using a variety of options. This can lead to a somewhat complex command structure, but once you understand the various options and their meanings, it's not too difficult to get the hang of. The following options can be added to grep to enhance its capabilities:
-i: Displays lines that meet the criteria, regardless of case sensitivity (Upper/Lowercase).-l: Displays only the filenames.-n: Displays lines that meet the criteria along with their line numbers.-c: Counts the number of lines that meet the criteria.-color: Colours matching results to make them stand out, if your terminal does not support them by default.-r: Performs a recursive search within directories and subdirectories.-v: Displays lines that do not meet the criteria (grep invert match / reverse search).-w: Displays matches of entire words.-A n: Displays n lines following matches.-B n: Displays n lines preceding matches.-C n: Displays n lines both before and after matches.
When including options, the grep syntax is:
grep -options "string to search for" filenameWe'll cover some ways you can use these options below.
Using grep for recursive search
By default, grep will only look in the files you specify for matches. Grep recursive search (-r) enables you to expand the search to a directory and all of its subdirectories.
Recursive grep comes in two forms:
grep -r: Looks for matches across all subdirectories but does not follow symbolic links.grep -R: Does the above but also follows symbolic links.
Therefore, if we wanted to search for all matches for the string "upon" across all directories, without following symbolic links, we could use:
grep -r "upon" *Or, to look for "upon" in a specific directory, following its symbolic links:
grep -r "upon" /home/root/documentsWhen performing recursive searches, you must be a bit careful so that you do not miss files and create slow searches or unintended output. Make sure to:
- Use -r and -R correctly. Not using -R when there is a symbolic link may cause you to miss files. However, before using -R, ensure there are not circular symlinks. Otherwise, you may end up searching the same directory multiple times.
- Be aware of binary files. Binary files will not be correctly processed unless you use grep --binary-files=text, but this may still contain some incomprehensible output. You can consider excluding binary files from your search (-rI).
- Exclude/include unnecessary directories to limit search time and output. There are likely some subdirectories you don't need to search. Using the --include and -exclude options will help to limit your search. For example,
grep -r --exclude-dir={.git, node_modules} "pattern" /path/to/dir. - Use sudo when searching in restricted directories. Otherwise, you will run into a flood of "Permission denied" messages.
How to use regular expressions with grep
You can think of regular expressions as a form of smart filter that can be used to create a search pattern. They start to make a lot more sense once you have an idea of what each expression does. Here's a handy regular expression cheat sheet:
| Pattern | Meaning | Example Match |
|---|---|---|
a-z | Any lowercase letter (a to z) | Matches a, b, c in "abc" |
A-Z | Any uppercase letter (A to Z) | Matches X, Y, Z in "XYZ" |
0-9 | Any digit (0-9) | Matches 4 in "A4B" |
. | Any character | Matches a, b, c in "abc" |
^ | Start of line | ^Hello matches "Hello world" but not "world Hello" |
$ | End of line | world$ matches "hello world" but not "world hello" |
\d | Any digit (0-9) | Matches 4 in "A4B" |
\w | Any letter, number, or underscore | Matches A, 4, _ in "A_4" |
\s | Any whitespace (space, tab, newline) | Matches space in "hello world" |
\b | Word boundary | \bcat\b matches "cat" but not "cats" |
[] | Match any of the characters inside | [aeiou] matches vowels |
[^] | Match anything except characters inside | [^aeiou] matches consonants |
* | Zero or more repetitions | ab* matches "a", "ab", "abb", "abbb" |
+ | One or more repetitions | ab+ matches "ab", "abb", but NOT "a" |
? | Zero or one occurrence | colou?r matches "color" and "colour" |
{n,m} | Between n and m occurrences | a{2,4} matches "aa", "aaa", "aaaa" but NOT "a" |
| `|` | OR (alternative match) | once|upon matches "once" or "upon" |
() | Grouping | (ab)+ matches "ab", "abab", "ababab" |
As you can imagine, combining multiple of these can be very powerful when you're trying to find specific information across a large dataset. For example, if we wanted to return all and only email addresses, we could use:
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}Let's break this down:
[a-zA-Z0-9._%+-]+: Looks for a string that contains at least one character of (the + at the end) the following:- lowercase letters (a-z)
- uppercase letters (A-Z)
- digits (0-9)
- full stops/dots (.)
- underscores (_)
- percentage symbols (%)
- plus symbols (+)
- hyphens (-)
@: Looks for an @ after the initial string above[a-zA-Z0-9.-]: We look for the domain name component of the email after the @, which can contain fewer valid characters. We are searching for at least one character of:- lowercase letters (a-z)
- uppercase letters (A-Z)
- digits (0-9)
- full stops/dots (.)
- hyphens (-)
\.: This is just searching for the . before the domain extension (i.e. the . of .com)[a-zA-Z]{2,}: Looks for a domain extension that contains only the letters a-z in lower or uppercase. The {2,} specifies that it must be at least two characters, but there is no upper limit.
As you can imagine, you can combine regular expressions like this to accurately return results for practically any information, saving a lot of manual data sorting and processing.
grep vs. egrep – what's the difference?
egrep supports a different range of regular expressions to grep. Grep uses basic regular expressions (BRE), which require metacharacters such as ?, +, {}, |, and () to be escaped with a . egrep, meanwhile, does not require escaping the above characters, allowing cleaner syntax.
These days, however, egrep is largely deprecated. Instead, it is recommended to use grep -E, which does essentially the same thing.
Using grep to invert output (grep -v)
Sometimes you want to find every line that does not match your pattern. -v inverts the match to say "bring me every line that doesn't include x".
Using our earlier server.log file, suppose we want to see everything that isn't an error so we can review normal activity. We can run:
grep -v "Error" server.logThis will give us the startup and connection lines while filtering out the error entries.
Starting server...
Connection established.
ERROR: Failed to load configuration. <-- removed by grep -v
Warning: Low disk space.
Error: Disk write failed. <-- removed by grep -v
Warning: High memory usage.How to grep for multiple strings/patterns
Grep allows you to search for multiple strings/patterns in a file by separating them with the |, enclosing the strings in single quotes, and adding a \ at the end of each string other than the final one. You can think of it as a grep OR condition. For example:
grep 'once\|upon' bitlaunch.txtFor easier syntax, you can use grep -e, which allows you to specify multiple patterns individually:
grep -e "once" -e "upon" bitlaunch.txtIf you are using regular expressions (grep -E), the syntax is as follows:
grep -E 'once|upon' bitlaunch.txtUsing case-insensitive grep
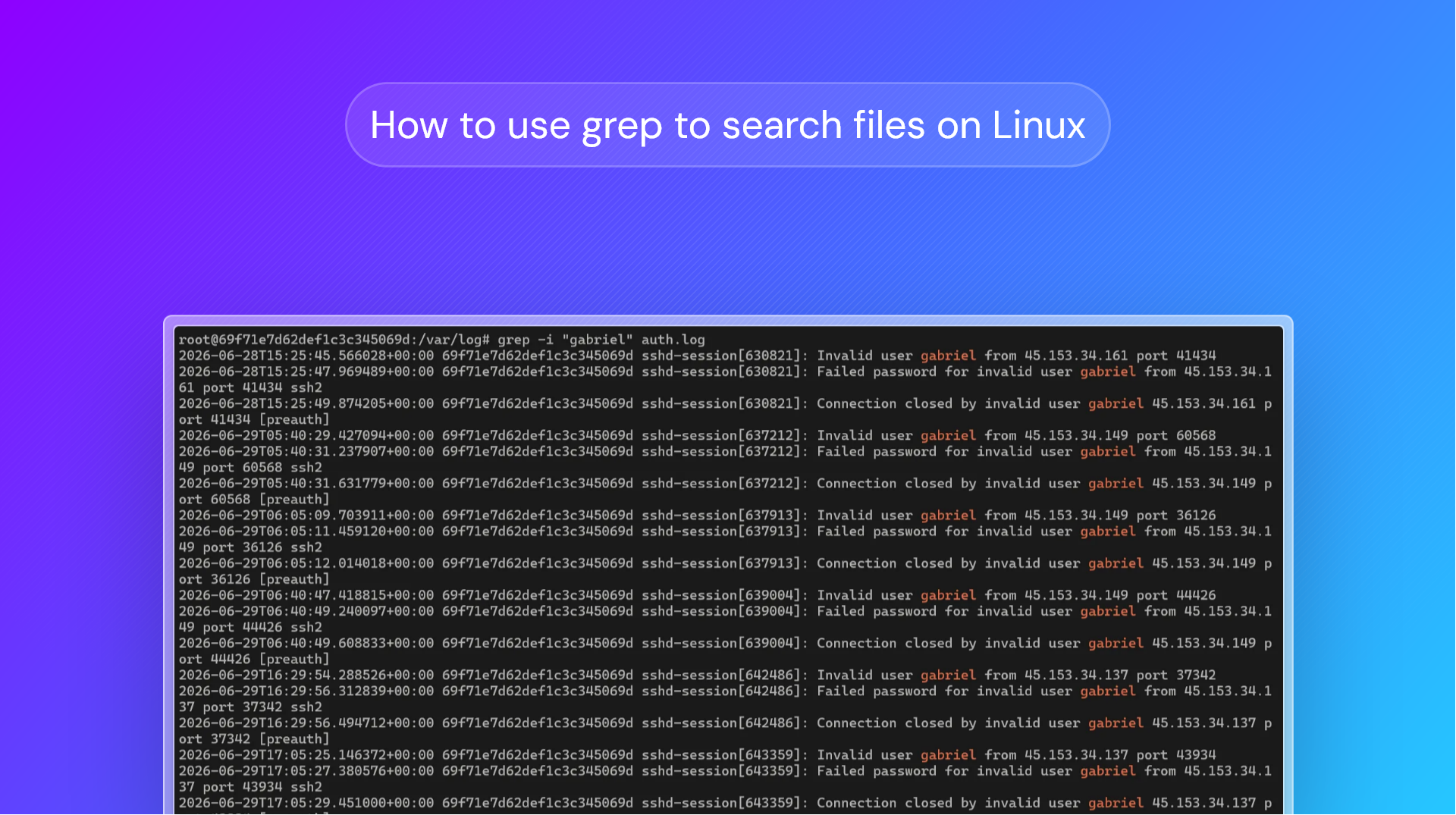
Adding the -i option tells grep to ignore case. Using grep case-insensitively means you'll still get a result if your search term doesn't perfectly match the capitalization of the string in your file.
Let's give an example. We have a text file that starts:
Once upon a time, there was a VPS provider called BitLaunch, known across the land for offering fast, reliable, and anonymous virtual servers.
It was said that once you tried BitLaunch, you'd never look back.Searching this file with grep "once" bitlaunch.txt will return the following:
Now let's search it case-insensitively using:
grep -i "once" bitlaunch.txtOur grep search now returns both instances of "once":
How to use pipes with grep
Pipes in Linux allow you to take the output of one command and use it as input to another. This enables grep to become even more powerful. The syntax for a grep command that uses pipes is as follows:
command file.extension | grep "phrase"Let's use an example:
journalctl -u sshd | grep "Failed password" | grep "root"In this case, journalctl -u sshd fetches the logs from the SSH service and passes the output to grep, which then looks for instances of "Failed password". This output is piped to another grep command, which filters the data to include only failed login attempts for the root user.
grep output can also be piped to other packages/applications. For example, grep "failed" auth.log | wc -l would use wc to count the number of matching lines in the grep output and, therefore, how many login failures occurred.
How to search for whole words with -w
Grep matches your pattern anywhere it appears by default, including in the middle of larger words.
Let's say we're grepping novel.txt, which has the following lines in various places.
Greta sat in the corner, reading absorbedly from a thick tome.
When she was a child, her mother combed her hair with such vigor that her scalp would hurt for days.
The smugglers bribed the port guards to look the other way.
Greta was just glad to have a bed and a roof over her head.If we used grep bed novel.txt, we'd get all four lines, with the search picking up on the bed in absorbedly, combed, bribed, and bed.

Using grep -w bed novel.txt, we get only the line "Greta was just glad to have a bed...", since it searches for words that contain just "bed" and nothing else.

This might not be too important in casual usage since you can just search through the list, but if you're writing a script it may be much more important to ensure you're not outputting lines that don't match your query.
How to show the lines before and after a match
Grep prints only the matching line by default, which is fine for most scenarios. When you're digging through logs, however, the context of surrounding lines can be very valuable. There are three options for showing additional lines that are worth exploring:
grep -A 1shows one line after each matchgrep -B 2shows two lines before each matchgrep -C 3shows 3 lines before and 3 lines after each match.
In our error log example, grep -B 2 "Disk write failed" server.log would therefore return:
3: ERROR: Failed to load configuration.
4: Warning: Low disk space.
5: Error: Disk write failed.It's worth noting that when grep returns multiple matches with overlapping or separate context blocks, it inserts a – between them so that you can tell the groups apart.
Next steps
Mastering grep is essential if you plan to be a sys admin, server admin, developer, or dev ops engineer. While grep's various options may feel overwhelming at first, learning to use regular expressions, recursive searching, and pipes will save you hundreds of hours of manual data processing and aid powerful shell scripts.
From here, it's worth practicing grep against your own log files or codebases rather than just toy examples, since real-world output is messier and will force you to combine options like -i, -r, and -E to get useful results. Once you're comfortable with the basics, look into using grep with shell variables for dynamic searches, chaining it with other text-processing tools like sed, awk, and sort, and exploring tools like ripgrep (rg) for faster recursive searches on large codebases.
We've covered all of the key grep examples and options here, but it's always worth reading the documentation for more detail.
FAQs
How do I search all files in grep?
Use a wildcard in place of a filename. grep "pattern" * searches every file in the current directory. To include subdirectories, add -r for a recursive search: grep -r "pattern" *.
How do you find text with grep in Linux?
Run grep "string to search for" filename. This returns every line in the file containing an exact (case-sensitive) match. Add -i for case-insensitive matching, or -n to show line numbers alongside results.
How can I search with grep recursively?
Use grep -r "pattern" /path/to/directory to search a directory and all its subdirectories without following symbolic links, or -R to also follow them. Combine with --exclude-dir to skip folders like .git or node_modules and keep searches fast.
What's the difference between grep and awk?
At its core, grep is a line filtering tool. It scans text and gives the user full lines that match a pattern. awk is a fully-fledged text-processing language that manipulates and extracts data, performing calculations, reformating output, and so on. They're often piped together, with grep performing the searching and awk formatting the output.
Can grep be used in shell scripts?
Yes. grep is a very powerful tool in shell scripts, allowing scripters to validate file contents, filter output, trigger conditional logic if a pattern is found, and so on.