
How to use cURL to download a file
curl -O https:///linktofile.com/file.zipcurl -o filename.extension linktofile.com/file.zip
Though there are a few command-line tools a Ubuntu VPS can utilize to download files, Client URL (cURL) is one of the most used, alongside systemctl and the export command. Its inclusion with most Unix-like operating systems and wide protocol support have made it a mainstay for server admins.
Today, we'll walk you through everything you need to know about using curl to download files, including what it is, its basic and advanced functions, and how to use it in the real world.
Don't have a Linux machine? Sign up to BitLaunch and use one of our VMs to perform a cURL download.
What is the cURL cmd?
Client and URL (cURL) is a command-line tool that transfers data to or from a server of your choice. It allows you to specify a URL and the data you want to send or receive from that URL using protocols such as HTTP, FTP, and IMAP.
In day-to-day Linux use, cURL is often used like a web browser — to download a file from a specific page from within the command line. However, it's also commonly used by developers in scripts to automate data transfers, test server response times, scrape webpages, and so on.
How to use cURL: The core commands
Most users will just want to use cURL to download a file, and the good news is that its developers have made doing so very simple. The basic syntax for curl is:
curl http://yoururl.filenameLet's look at how we can use it to view a file in the command line and save it with both its original filename or a custom name or path. Our sample file will be the readme for blcli, BitLaunch's command-line interface, which is hosted on GitHub.
How to use cURL to view a remote file
If you stick to the basic syntax above, cURL will display your downloaded file in the command line if it can. Using your readme as an example, we can use:
curl https://raw.githubusercontent.com/BitLaunchIO/blcli/master/README.mdTo view the bcli readme in our terminal.
How to use cURL to download a file with its original filename
So what if we want to use cURL to save a file to our anonymous VPS server with its original filename? For that, we must use the -O option:
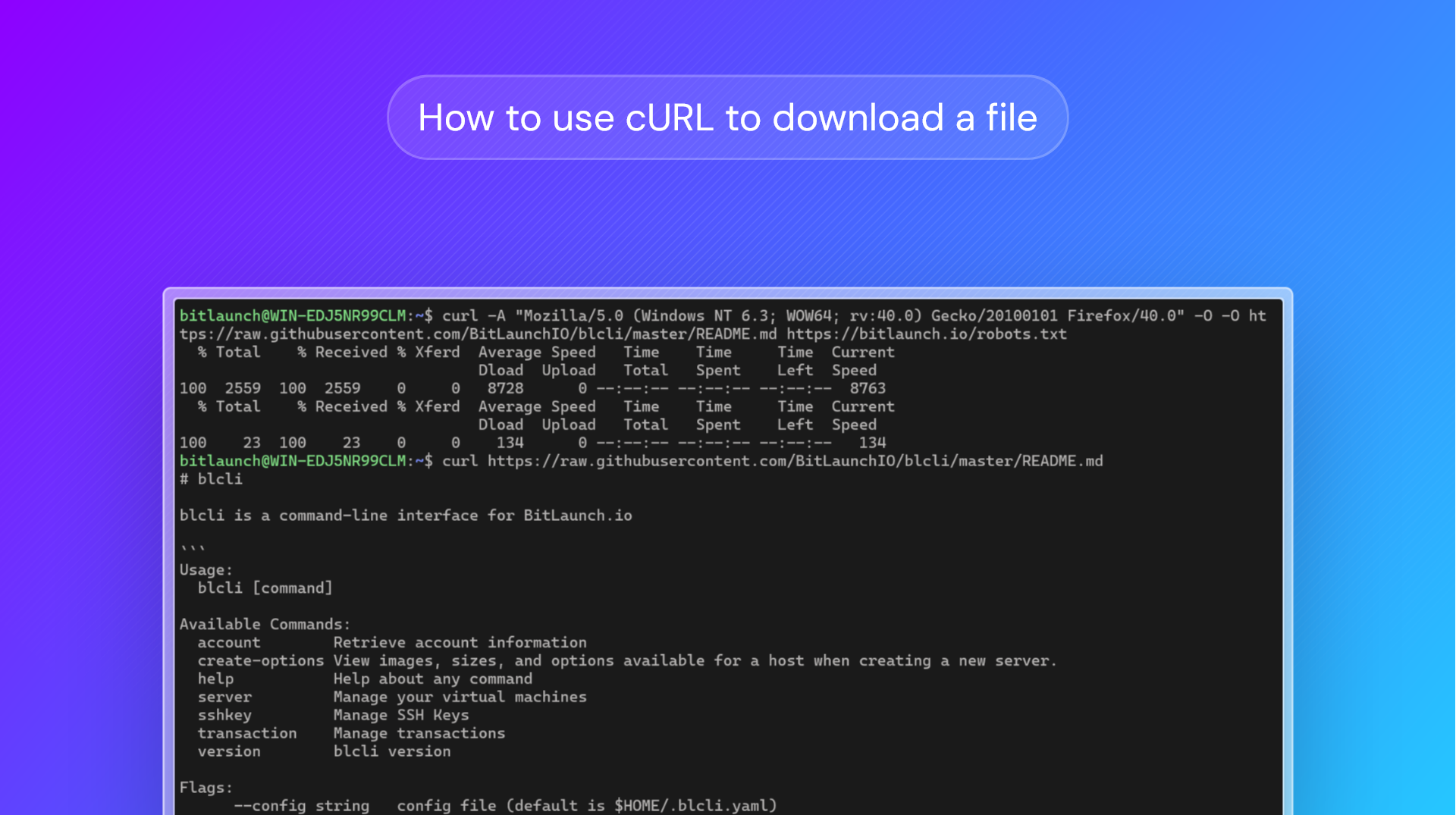
curl -O https://raw.githubusercontent.com/BitLaunchIO/blcli/master/README.md
You'll notice that cURL will display a download progress table rather than the file contents this time:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2559 100 2559 0 0 17174 0 --:--:-- --:--:-- --:--:-- 17174
To verify that the file has downloaded, we can then type nano README.md. Check out this guide if you need help deleting a line in nano.
How to use cURL to save to file
If you'd like the file you're downloading to have a different file name, specify it after -O :
curl -o dontreadme.md https://raw.githubusercontent.com/BitLaunchIO/blcli/master/README.mdYou should then be able to read the file with sudo nano dontreadme.md. If you want to save the file to a specific location, just append the path before the filename:
curl -o your/path/dontreadme.md https://raw.githubusercontent.com/BitLaunchIO/blcli/master/README.mdYou can navigate to the output folder using cd and then run ls to ensure the file is present.
Get cURL to follow redirects
As it's common for site admins to move the location of a file, then 301 redirect to the new one, it can be good practice to include the -L option in your cURL command.
For example, if we try to access BitLaunch's robots.txt with this command:
curl -O www.bitlaunch.io/robots.txt
You get no output. That's because www.bitlaunch traffic is redirected to https://bitlaunch. If we use curl -L -O www.bitlaunch.io/robots.txt, cURL will follow any redirects:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 23 100 23 0 0 82 0 --:--:-- --:--:-- --:--:-- 82
You can see that there are two rows in our download table that didn't download any data. These are the URLs that were redirected. We can review this redirect chain with:
curl -v www.bitlaunch.io/robots.txt
Using cURL with FTP
cURL isn't limited to HTTP. One of its strengths over a browser is native support for FTP, which makes it handy for pulling files from or pushing files to an FTP server straight from the command line.
To download a file from an FTP server, the syntax is the same as any other cURL download, just with an ftp:// URL:
curl -O ftp://ftp.example.com/files/archive.tar.gzIf the server requires a login, pass your credentials with the -u flag:
curl -u username:password -O ftp://ftp.example.com/files/archive.tar.gzFor servers that use FTPS (FTP over SSL/TLS), swap the protocol for ftps:// to encrypt the connection.
How to use advanced Linux cURL commands
In addition to its basic syntax, there are several more advanced ways to use cURL to download multiple files, use a specific user agent, and more.
Use cURL to download multiple files
That's all well and good, but downloading many files this way would quickly become a hassle. You can download more than one file in a single command by using the following syntax:
curl -O -O https://raw.githubusercontent.com/BitLaunchIO/blcli/master/README.md https://bitlaunch.io/robots.txt% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2559 100 2559 0 0 5067 0 --:--:-- --:--:-- --:--:-- 5067
100 23 100 23 0 0 101 0 --:--:-- --:--:-- --:--:-- 101
You'll see that this time the output lists two rows for downloads - both of our files.
If both files are in the same sub-directory on the same site, it's even easier:
curl -O -O` [`https://raw.githubusercontent.com/BitLaunchIO/blcli/master/`](https://raw.githubusercontent.com/BitLaunchIO/blcli/master/LICENSE.txt)`{README.md,LICENSE.txt}`
Or, if you want to download a series of files in the same directory that are numbered:
curl examplewebsite.com/filename[1-20].jpeg
If you have a long list of different files you want to download, you can place them in a text file and run cURL with xargs:
`xargs -n 1 curl -O fileurls.txt`
You'll get the normal download output with each file transfer listed in its own row.
Downloading with cURL using a specific user agent
The cURL -A flag is a useful advanced feature that lets you bypass compatibility blocks, obscure your cURL fingerprint, and test a web app as if you were on a mobile device. The syntax to use it looks something like this:
curl -A "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0" -L google.com.
We won't list every possible user agent here, but here are a few of the most useful:
| Use Case | User Agent String |
|---|---|
| Chrome (Windows) | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 |
| Chrome (macOS) | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 |
| Firefox (Windows) | Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0 |
| Safari (iPhone) | Mozilla/5.0 (iPhone; CPU iPhone OS 17_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.5 Mobile/15E148 Safari/604.1 |
| Android Chrome | Mozilla/5.0 (Linux; Android 14; Pixel 8) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Mobile Safari/537.36 |
| Googlebot | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Default cURL | curl/8.7.1 |
Automating cURL downloads with shell scripts
In a development environment and sometimes even as a server admin, knowing how to write a basic script to download files with cURL is incredibly useful. We'll combine the other advanced functions above to create a script that grabs URLs from a list and downloads them to a specific directory using a specific user agent.
#!/bin/bash
USER_AGENT="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
# Text file in the same directory containing one URL per line
URL_LIST="fileurls.txt"
DEST_DIR="/downloads"
xargs -n 1 curl -O -L --output-dir "$DEST_DIR" -A "$USER_AGENT" < "$URL_LIST"
echo "Downloads complete. Files saved to $DEST_DIR/"
Essential cURL flags
We've covered the most common options above, but cURL has a huge range of flags worth keeping in your back pocket. Here are the essential ones:
| Flag | Long form | What it does |
|---|---|---|
-O |
--remote-name |
Saves the file using its original remote filename |
-o |
--output |
Saves the file under a name or path you specify |
-L |
--location |
Follows redirects to the file's final location |
-A |
--user-agent |
Sets a custom user agent string |
-v |
--verbose |
Verbose mode; shows the full request and redirect chain for debugging |
-s |
--silent |
Silent mode; hides the progress meter and error messages |
-I |
--head |
Fetches only the HTTP response headers, not the body |
-C - |
--continue-at - |
Resumes an interrupted download from where it stopped |
-x |
--proxy |
Routes the request through a proxy server |
-u |
--user |
Passes a username and password for authentication |
-d |
--data |
Sends data in a POST request |
-H |
--header |
Adds a custom request header |
-k |
--insecure |
Allows connections to sites with invalid SSL certificates |
--limit-rate |
— | Caps the download speed (e.g. --limit-rate 200k) |
Troubleshooting common curl download issues
If curl is failing to download your file, it's usually one of these problems:
- A user agent restriction:
You can confirm whether the server needs a non-default user agent to fetch the file withcurl -A "Mozilla/5.0" -O https://website.com/file.jpg - Wrong protocol:
Sometimes old sites don't support HTTPS, and appending it in front of the file causes the download to fail. Try using http instead:curl -O http://website.com/file.jpg - You're using the right protocol, but SSL/TLS is broken on the site:
-vis a very useful flag in these scenarios. It allows you to see the full request chain so you can pinpoint where it's going wrong. For example:curl -v -O https://website.com/file.jpg. You can choose (at your own risk) to download files from websites with an invalid certificate usng the-kflag:curl -k -O https://website.com/file.jpg. - Authentication issues:
Some servers require logging in or a token to download files, in which case you'll need to provide the credentials to cURL usingcurl -u username:password -O https://website.com/file.jpgorcurl -H "Authorization: Bearer YOUR_TOKEN" -O https://api.website.com/file.json
Using wget as an alternative to cURL
cURL is an excellent tool, but wget is a better choice in some scenarios. While the tools perform somewhat similar purposes, there are some distinct differences in features.
cURL vs wget
While cURL and wget are both command-line download tools, they're ultimately built for different jobs. wget is focused specifically on downloading, while cURL is more of a general-purpose data transfer tool that handles downloads and uploads with fine-grained control and wider protocol support.
When to use cURL
cURL should be your go-to when you need to send data as well as receive it or want more control over your requests. It's still great for general-purpose downloads, but it does less automatically than wget and lacks features like retrying failed transfers, following redirects, and performing recursive downloads. Where it really shines, therefore, is in scripting, API testing, scraping, and so on.
When to use wget
wget is the better choice in some download situations. Its recursive and mirroring features wget -r or wget -m makes it ideal for crawling and downloading an entire site for a directory tree while preserving the folder structure. It's also better on unstable connections or when downloads are unattended, since it automatically retries 20 times by default, can be used with -b for background downloads, and allows you to set speed limits (wget --limit-rate=200k https://website.com/file.tar.zip).
Overall, wget is usually the better choice when the task is purely about fetching files, especially in bulk. It has more sensible defaults for one-off downloads, such as not needing -O to save with the original filename, and has simpler syntax.
Real-world applications of Linux cURL in VPS servers
We've talked about how cURL can be useful in sysadmin and scripting, but haven't gone into detail with specific commands and use cases. Here are some examples of how you could start using cURL today to administer your server.
Checking health and uptime
While there are better ways to monitor uptime, such as server management tools, a simple approach is a cron-friendly script that checks the website's HTTP status codes. You can run this on a machine other than the server to determine the website's status from a user's perspective.
#!/bin/bash
URL="https://yoursite.com"
WEBHOOK_URL="https://discord.com/api/webhooks/YOUR/WEBHOOK/URL"
STATUS=$(curl -s -o /dev/null -w "%{http_code}" --max-time 10 "$URL")
if [ "$STATUS" -ne 200 ]; then
curl -s -H "Content-Type: application/json" \
-d "{\"content\":\"$URL is DOWN (status: $STATUS)\"}" \
"$WEBHOOK_URL"
fiHere, we use cURL twice: once to check the endpoint for the HTTP code, then again to push the code to our webhook if the status is anything other than 200. We'll explain the syntax of each:
STATUS=$(curl -s -o /dev/null -w "%{http_code}" --max-time 10 "$URL")Here, cURL is wrapped in the STATUS$(), which ensures the output is saved to the status variable. We then run curl -s for silent operation. -o /dev/null outputs the body HTML of the page to /dev/null, Linux's "discard this" folder. Essentially saying "discard the stuff we don't need". Critically, -w "%{http_code}" then tells cURL to write out (print) the HTTP status code after waiting a maximum of 10 seconds before it's treated as a failure. We then log the $URL in question so we can differentiate in our webhook later.
If the result of cURL script is not the HTTP status 200, which means normal functioning, the second cURL command runs:
curl -s -H "Content-Type: application/json" \
-d "{\"content\":\"$URL is DOWN (status: $STATUS)\"}" \
"$WEBHOOK_URL"Again, the -s flag ensures this runs silently without a progress bar. -H "Content-Type: application/json adds a request header telling Discord that we'll be giving it a JSON output so that it knows what to parse. The -d flag tells cURL we want to POST (send) HTTP information rather than GET (receive) it, since it's going to our webhook. Everything after that is the data we want to send, with the $URL and $STATUS pulled from those variables we defined earlier to deliver the message: yourwebsite.com is DOWN status: 500.
Interacting with a REST API
Millions of developers and server admins use REST APIs daily to control services programmatically. In this example, we'll use cURL with the BitLaunch API to list the active servers on our account:
#!/bin/bash
BL_TOKEN=$(cat /etc/bitlaunch/token)
curl -s -H "Authorization: Bearer $BL_TOKEN" \
https://app.bitlaunch.io/api/servers \
| jq -r '.[] | "\(.name) \(.ipv4) \(.status)"'Here, we can use a rather simple cURL command. curl -s makes the command run silently in a script-friendly way. -H adds a custom header to the request with our authorization token to prove we're allowed to make the request.
Sign up to BitLaunch and launch a VPS in Amsterdam, Bucharest, or the USA within minutes. Launch servers programmatically to use with cURL, or use our control panel to select from various regions and VPS providers. The \ tell cURL the command continues on the next line and then specifies the API endpoint to fetch our server information. We then pipe it to jq to grab only the information we're looking for in a readable format (the name, IP, and status). Giving us something like:
my-server 69.67.128.25 ok.
my-server2 62.69.123.12 ok.Taking cURL further
The flags and patterns in this guide will cover the vast majority of what you'll encounter day-to-day, but cURL's full documentation is worth bookmarking for the edge cases. The tool has well over a hundred options and endless ways of using them in scripts; explaining every one isn't within the scope of this guide. In particular, the art of scripting HTTP requests is worth a read, since it covers writing scripts for various scenarios and use cases.
Need a test environment? Sign up to BitLaunch and launch a VPS in Amsterdam, Bucharest, or the USA within minutes. Launch servers programmatically to use with cURL, or use our control panel to select from various regions and VPS providers.
FAQs
When should you use quotes in cURL commands?
You need quotes whenever an argument contains characters your shell treats specially, otherwise the shell mangles the command before cURL ever sees it. When using [] or {} sequences, you probably have to put the full URL within double quotes to avoid the shell interfering with it, and the same goes for characters like &, ? and *. The practical rule is to wrap any URL with a query string, and any -d or -H value, in quotes. Single quotes are usually safer than double quotes because they stop the shell from expanding variables inside them, which makes them the better choice for JSON payloads, which are full of double quotes already.
Is cURL available on Windows?
Yes. Since Windows 10 Insider build 17063, every installation of Windows 10 and Windows 11 has curl installed by default. On older Windows versions, you can download the binary from curl.se/windows.
How do I monitor cURL download progress?
cURL shows a progress meter by default, but it's inhibited if cURL deems output is going to the terminal, so if you don't see it, make sure your output is directed somewhere other than the terminal (using -O or -o does this). For something cleaner, -# or --progress-bar shows the transfer as a single bar instead of the default meter table.
How can I use cookies with cURL?
cURL's cookie engine is off by default. You turn it on by reading or writing cookies. Use -c (--cookie-jar) to write cookies received from the server into a file, and -b (--cookie) to send them back, either from that file or as a literal string like -b "session_id=abc123".
How do I send custom headers with cURL?
Use -H (--header) followed by the header in Name: Value form, exactly as covered earlier with the BitLaunch token. You can repeat -H as many times as you need, one per header.
How do I deal with rate limiting when downloading with cURL?
To avoid tripping rate limits, you can throttle yourself. --rate caps how many transfers cURL makes per unit of time. For example, curl --rate 2/s -O https://example.com/[1-100].jpg downloads 100 images no faster than two per second, and --limit-rate 200k caps raw bandwidth instead. When you do get rate-limited (429 code), wait the specified time before retrying more cautiously, or use a proxy with the --proxy flag to reset it instantly.